“Not everything that can be counted counts, and not everything that counts can be counted.”
— William Bruce Cameron
5.1 Do indicador simples ao índice composto
Nos capítulos anteriores, discutimos como variáveis são medidas e como estatísticas descritivas permitem resumir distribuições. Um passo natural dessa lógica de síntese é a construção de indicadores — medidas que representam, de forma indireta mas quantificável, algum aspecto da realidade social que não pode ser diretamente observado em sua totalidade. A taxa de mortalidade infantil, por exemplo, não mede apenas mortes: ela é um indicador das condições gerais de saúde, saneamento e qualidade de vida de uma população. O percentual de pessoas com ensino fundamental completo indica algo maior do que escolaridade — indica oportunidades, capacidades e perspectivas de vida.
Quando um único indicador é construído a partir de uma estatística específica, referida a uma dimensão social delimitada, falamos de indicador simples ou analítico. A taxa de desemprego, a taxa de evasão escolar e a proporção de domicílios com saneamento adequado são exemplos: cada um capta uma dimensão precisa da realidade e responde a uma pergunta concreta.
Há situações, porém, em que se deseja capturar fenômenos intrinsecamente multidimensionais — como pobreza, desenvolvimento humano, vulnerabilidade social ou responsabilidade fiscal. Nesses casos, nenhum indicador isolado é suficiente. A solução adotada por pesquisadores e agências estatísticas é combinar dois ou mais indicadores simples em uma única medida, formando o que se chama de indicador composto, indicador sintético ou índice social. Como define Jannuzzi (2001), indicadores compostos “são elaborados mediante aglutinação de dois ou mais indicadores simples, referidos a uma mesma ou diferentes dimensões da realidade social”.
Essa hierarquia está representada na pirâmide clássica do Ministério do Planejamento (Figura 5.1): na base estão os dados originais; acima, os dados analisados e os indicadores; no topo, os índices compostos. O grau de agregação aumenta de baixo para cima, assim como a quantidade de informação combinada.
graph TB A[Dados originais] --> B[Dados analisados] B --> C[Indicadores analíticos] C --> D[Índices compostos] style D fill:#c0392b,color:#fff style C fill:#e67e22,color:#fff style B fill:#f39c12,color:#fff style A fill:#27ae60,color:#fff
graph TB
A[Dados originais] --> B[Dados analisados]
B --> C[Indicadores analíticos]
C --> D[Índices compostos]
style D fill:#c0392b,color:#fff
style C fill:#e67e22,color:#fff
style B fill:#f39c12,color:#fff
style A fill:#27ae60,color:#fff
Figura 5.1: Da dados brutos aos índices: hierarquia de agregação da informação
A construção de um índice composto envolve sempre três perguntas centrais que não têm resposta única nem neutra (OCDE; Joint Research Centre – European Commission, 2008): Que dimensões incluir?Como combinar os indicadores?Que pesos atribuir a cada um? Essas escolhas têm consequências práticas diretas: municípios que se classificam bem em um arranjo de pesos podem se classificar mal em outro. Por isso, a transparência metodológica é considerada condição necessária para o uso responsável de índices compostos em políticas públicas.
5.2 Por que construir indicadores sintéticos?
A justificativa para agregar múltiplos indicadores em um único número não é trivial. Afinal, qualquer processo de síntese implica perda de informação: ao resumir em um número o que antes eram várias dimensões distintas, é inevitável que diferenças importantes entre unidades sejam apagadas.
Síntese comunicativa: um único número é mais facilmente compreendido por gestores, jornalistas e pela opinião pública do que uma bateria de indicadores individuais. O IDH, por exemplo, ganhou enorme repercussão precisamente porque traduz em um único valor a complexidade de três importantes dimensões do bem-estar humano.
Facilidade de comparação: índices permitem ranquear municípios, estados ou países ao longo do tempo e entre si, facilitando análises comparativas.
Monitoramento de tendências: ao permitir comparações temporais, índices compostos tornam possível avaliar se uma área está progredindo ou regredindo em relação a um conjunto de dimensões.
Apoio à tomada de decisão: gestores públicos podem usar índices como ferramentas para priorizar ações, identificar áreas de carência e avaliar resultados de políticas.
Estímulo ao debate público: a visibilidade conferida pelos índices aos temas sociais — desigualdade, pobreza, vulnerabilidade — contribui para a accountability dos gestores e para a mobilização da sociedade civil.
Essas vantagens, contudo, têm custos. Guimarães; Jannuzzi (2005) destacam que indicadores sintéticos também podem distorcer a realidade se construídos inadequadamente, induzir conclusões simplistas se mal interpretados e tornar-se objeto de disputas políticas na definição de pesos e dimensões. Um índice que combina tendências que caminham em direções opostas — como uma redução da mortalidade infantil simultânea ao aumento do desemprego — pode sinalizar “progresso” ou “retrocesso” dependendo de como os componentes são ponderados, sem revelar nada sobre nenhum dos processos individuais.
Essa tensão entre síntese e detalhe é estrutural. O bom uso de indicadores sintéticos exige que o analista mantenha sempre em perspectiva os indicadores componentes, evitando substituir o conceito subjacente pela medida operacional que o representa — um problema que Guimarães; Jannuzzi (2005) chamam de “reificação da medida em detrimento do conceito”.
5.3 As etapas de construção de um índice composto
O Handbook on Constructing Composite Indicators da OCDE (2008) organiza a construção de índices compostos em dez etapas. Seguir esse roteiro não garante um índice “correto” — não há tal coisa —, mas estrutura o processo de forma transparente e metodologicamente defensável.
1. Marco teórico e conceitual. Antes de qualquer cálculo, é necessário definir claramente o conceito que se pretende medir. Desenvolvimento humano, responsabilidade social, vulnerabilidade e qualidade de vida são constructos abstratos e multidimensionais; qualquer índice que os represente é uma escolha entre alternativas igualmente plausíveis. O marco teórico delimita quais dimensões são relevantes e por quê.
2. Seleção de dados. A partir do marco teórico, identificam-se os indicadores disponíveis para representar cada dimensão. Critérios como cobertura geográfica, periodicidade, fonte e qualidade dos dados orientam essa seleção. Nem sempre o indicador teoricamente ideal é o que está disponível — e isso é uma limitação que deve ser explicitada.
3. Imputação de dados ausentes. Bases de dados reais raramente estão completas. A forma como valores ausentes são tratados — exclusão das unidades, imputação pela média, modelos de imputação — afeta os resultados e deve ser documentada.
4. Análise multivariada exploratória. Antes de combinar indicadores, convém examinar a estrutura de correlação entre eles. Indicadores altamente correlacionados capturam essencialmente a mesma informação; incluí-los com o mesmo peso pode superponderar uma dimensão. Técnicas como análise fatorial ou de componentes principais ajudam a identificar a estrutura subjacente dos dados.
5. Normalização. Como os indicadores originais têm unidades e escalas muito distintas — anos de vida, percentuais, valores monetários —, é necessário padronizá-los antes de combiná-los. Os métodos mais comuns são a normalização min-max e a padronização z-score (Seção 5.4).
6. Ponderação e agregação. Após normalizar, define-se com que peso cada indicador entra no índice e como eles são combinados (média aritmética, média geométrica, soma ponderada). Essas escolhas são simultaneamente técnicas e políticas, e cada alternativa tem implicações distintas.
7. Análise de robustez. Um bom índice não deve ser excessivamente sensível a pequenas alterações metodológicas. Análises de sensibilidade — variando pesos, métodos de normalização e conjunto de indicadores — revelam o quanto o ranqueamento das unidades muda em função dessas escolhas.
8. Retorno às dimensões componentes. O índice final deve ser sempre lido em conjunto com os indicadores que o compõem. Um município com IDHM médio pode ter IDHM-Longevidade alto e IDHM-Educação baixo, e essa distinção importa para a política pública.
9. Vinculação a outros indicadores. A validade do índice pode ser avaliada verificando se ele se relaciona como esperado com outros indicadores externos ao processo de construção. O IDHM, por exemplo, deveria correlacionar-se com indicadores de pobreza, emprego e habitação.
10. Visualização e comunicação. A forma como o índice é apresentado — tabelas, mapas, gráficos — é fundamental para que seu significado seja compreendido corretamente pelo público não técnico.
5.4 Normalização: colocando indicadores na mesma escala
Um dos desafios centrais na construção de índices compostos é que os indicadores componentes geralmente têm unidades e escalas muito diferentes. A esperança de vida é medida em anos (tipicamente entre 40 e 85); o percentual de pessoas com ensino fundamental completo varia de 0 a 100; a renda per capita pode ir de alguns reais a vários milhares. Somar esses valores diretamente produziria um índice dominado pelas variáveis de maior magnitude, independentemente de sua relevância conceitual.
A solução é normalizar os indicadores — transformá-los de modo que passem a operar em uma escala comum. Dois métodos são amplamente utilizados.
5.4.1 Normalização min-max
O método min-max transforma o indicador de modo que o valor mínimo observado (ou um mínimo de referência) passe a valer 0 e o valor máximo (ou um máximo de referência) passe a valer 1. A fórmula é:
onde \(x_i\) é o valor observado para a unidade \(i\), \(x_{\min}\) é o mínimo de referência e \(x_{\max}\) é o máximo de referência.
Quando os valores mínimo e máximo são parâmetros de referência fixados externamente — e não apenas os valores extremos observados na amostra —, o método permite comparações temporais e entre diferentes recortes geográficos. É esse o caso do IDHM, onde os parâmetros são definidos a priori pela metodologia.
5.4.2 Padronização z-score
A padronização z-score transforma o indicador em termos de quantos desvios-padrão cada observação se afasta da média:
\[z_i = \frac{x_i - \bar{x}}{s}\]
onde \(\bar{x}\) é a média e \(s\) é o desvio-padrão do conjunto de dados. O resultado é uma variável com média zero e desvio-padrão um, o que facilita a comparação entre indicadores com distribuições distintas. A desvantagem é que os valores padronizados não têm uma interpretação intuitiva como “0 = pior situação possível, 1 = melhor situação possível”.
5.4.3 Qual método usar?
A escolha depende do objetivo. O método min-max é preferível quando se deseja interpretar os valores como posições entre um pior e um melhor cenário de referência — o que facilita a comunicação com públicos não técnicos e permite comparações temporais, desde que os parâmetros de referência sejam mantidos fixos. O z-score é mais adequado para análises que privilegiam a estrutura estatística dos dados e para modelos em que se deseja que cada indicador contribua proporcionalmente à sua variabilidade.
5.5 Métodos de agregação
Após normalizar os indicadores, é preciso decidir como combiná-los. Os dois métodos mais usados na prática de políticas públicas são a média aritmética e a média geométrica.
Sua principal propriedade — e também sua principal limitação — é a substituibilidade perfeita entre as dimensões: um valor muito baixo em uma dimensão pode ser compensado por valores altos em outras. Dois municípios com médias iguais mas perfis completamente distintos receberiam o mesmo índice, o que pode mascarar situações de carência grave em dimensões específicas.
A média geométrica elimina essa substituibilidade perfeita:
Com pesos iguais \(w_k = 1/K\), ela se reduz à raiz \(K\)-ésima do produto dos subíndices. A propriedade crucial é que, se qualquer subíndice for zero, o índice composto também será zero — não há compensação possível. Além disso, a média geométrica penaliza desigualdade entre as dimensões: um desempenho muito desigual entre elas produz um índice menor do que um desempenho equilibrado com a mesma média aritmética. Por essas razões, o IDHM adota a média geométrica na etapa de combinação final das três dimensões.
5.6 O IDHM: um estudo de caso detalhado
O Índice de Desenvolvimento Humano Municipal (IDHM) é a adaptação brasileira do Índice de Desenvolvimento Humano (IDH) para o nível municipal. Desenvolvido pelo PNUD Brasil, pelo IPEA e pela Fundação João Pinheiro a partir de dados do Censo Demográfico de 2010 — com recálculos retroativos para 1991 e 2000 —, o IDHM tem se consolidado como um dos principais instrumentos de diagnóstico territorial para políticas públicas no Brasil (PNUD Brasil; IPEA; Fundação João Pinheiro, 2013a).
O IDH surgiu em 1990, concebido pelo economista paquistanês Mahbub ul Haq com inspiração no pensamento de Amartya Sen. Sua premissa central é que o desenvolvimento humano vai além do crescimento econômico: envolve a ampliação das capacidades e liberdades das pessoas. Para operacionalizar essa ideia, o IDH combina três dimensões fundamentais: vida longa e saudável (longevidade), acesso ao conhecimento (educação) e padrão de vida decente (renda).
O IDHM “segue as mesmas três dimensões do IDH global — saúde, educação e renda, mas vai além: adequa a metodologia global ao contexto brasileiro e à disponibilidade de indicadores nacionais” (PNUD Brasil; IPEA; Fundação João Pinheiro, 2013a). Como os indicadores do IDH global — como anos esperados de escolaridade e Renda Nacional Bruta — não estão disponíveis para municípios, o IDHM usa alternativas mais adequadas à realidade municipal brasileira, especialmente as disponibilizadas pelo Censo Demográfico.
5.6.1 A dimensão Longevidade
A dimensão Longevidade do IDHM é medida pela esperança de vida ao nascer: o número médio de anos que uma pessoa nascida em determinado município viveria a partir do nascimento, mantidos os padrões de mortalidade do período. Esse indicador sintetiza em um único número o nível e a estrutura de mortalidade de uma população, incorporando todas as causas de morte — doenças e causas externas como violência e acidentes.
A transformação em subíndice segue a normalização min-max com parâmetros fixos:
\[\text{IDHM-L} = \frac{\text{Esperança de vida} - 25}{85 - 25}\]
Os valores de referência — mínimo de 25 anos e máximo de 85 anos — foram adotados por convenção metodológica para manter comparabilidade temporal. Assim, um município com esperança de vida de 70 anos obtém:
A dimensão Educação é a mais complexa das três, pois combina dois subíndices que captam aspectos distintos do acesso ao conhecimento:
Subíndice de escolaridade da população adulta — mede o percentual de pessoas de 18 anos ou mais com ensino fundamental completo. Como as taxas percentuais variam naturalmente de 0% a 100%, a normalização consiste simplesmente em dividir o valor por 100. Este subíndice recebe peso 1.
Subíndice de fluxo escolar da população jovem — mede a média aritmética de quatro indicadores de frequência/conclusão escolar em quatro momentos-chave da formação:
percentual de crianças de 5 a 6 anos frequentando a escola;
percentual de jovens de 11 a 13 anos nos anos finais do ensino fundamental;
percentual de jovens de 15 a 17 anos com ensino fundamental completo;
percentual de jovens de 18 a 20 anos com ensino médio completo.
Este subíndice recebe peso 2, refletindo a maior importância atribuída ao fluxo escolar contemporâneo em relação ao estoque histórico de escolaridade da população adulta.
A combinação dos dois subíndices usa a média geométrica ponderada:
A dimensão Renda é medida pela renda municipal per capita: a soma de todas as rendas dos residentes dividida pelo número total de habitantes, incluindo crianças e pessoas sem renda registrada.
A normalização da dimensão Renda aplica uma transformação logarítmica antes da normalização min-max:
O uso do logaritmo tem justificativa econômica: reflete a ideia de retornos decrescentes da renda para o desenvolvimento humano. Um acréscimo de R$ 100 na renda de uma pessoa que ganha R$ 200 representa um impacto muito maior do que o mesmo acréscimo para alguém que já ganha R$ 4.000. A transformação logarítmica captura essa assimetria ao comprimir os valores mais altos. Os parâmetros de referência são R$ 8,00 (mínimo, correspondente a aproximadamente US$ 100 PPC, limite adotado para o IDH global) e R$ 4.033,00 (máximo, correspondente à menor renda per capita entre os 10% mais ricos residentes no Distrito Federal, a UF de maior renda média do país no período).
5.6.4 O índice final e sua leitura
O IDHM final é a média geométrica dos três subíndices com pesos iguais:
O resultado é um número entre 0 e 1, classificado em cinco faixas:
Faixa de desenvolvimento
Intervalo
Muito Baixo
0,000 a 0,499
Baixo
0,500 a 0,599
Médio
0,600 a 0,699
Alto
0,700 a 0,799
Muito Alto
0,800 a 1,000
A evolução do IDHM dos municípios brasileiros entre 1991 e 2010 é ilustrativa: em 1991, 85,8% dos municípios estavam na faixa Muito Baixo; em 2010, essa proporção caiu para 0,6%, com 33,9% na faixa Alto e 40,1% na faixa Médio (PNUD Brasil; IPEA; Fundação João Pinheiro, 2013b). O município de maior IDHM em 2010 foi São Caetano do Sul (SP), com 0,862; o de menor foi Melgaço (PA), com 0,418. Em Minas Gerais, o maior valor foi Belo Horizonte e o menor São João das Missões (MG), com 0,529.
O uso da média geométrica no IDHM final tem uma consequência importante: a escolha não é indiferente à desigualdade entre as dimensões. Um município com subíndices 0,9; 0,9 e 0,1 obtém IDHM = \((0,9 \times 0,9 \times 0,1)^{1/3} \approx 0{,}45\), enquanto outro com subíndices equilibrados 0,63; 0,63 e 0,63 obtém IDHM = \(0{,}63\). O desempenho muito desigual é penalizado — o que reflete a premissa de que nenhuma dimensão pode compensar outra quando se trata de capacidades humanas básicas.
5.6.5 Limitações do IDHM
O IDHM é amplamente reconhecido como um instrumento valioso, mas seus limites precisam ser compreendidos para que não seja usado de forma inadequada. Guimarães; Jannuzzi (2005) identificam problemas que merecem atenção:
A média como ocultação: como todas as dimensões são médias, o IDHM mascara desigualdades internas. Municípios com alta renda per capita concentrada em poucos habitantes podem apresentar um IDHM-Renda elevado que não reflete a situação da maioria da população.
Substituibilidade na leitura: embora a média geométrica reduza a substituibilidade em relação à aritmética, dois municípios com o mesmo IDHM podem ter perfis completamente diferentes. O IDHM não substitui a análise dos subíndices e dos indicadores componentes.
Inadequação para elegibilidade: usar o IDHM como único critério de elegibilidade de municípios para políticas setoriais específicas pode levar a escolhas equivocadas. Guimarães; Jannuzzi (2005) mostram que municípios selecionados pelos 100 menores IDHMs nem sempre são os mais carentes quando avaliados por indicadores específicos do problema a ser enfrentado — como condições de saneamento, situação nutricional infantil ou acesso a serviços de saúde.
Base censitária: o IDHM é calculado com dados do Censo Demográfico, realizado a cada dez anos. Entre censos, os valores permanecem desatualizados, o que limita seu uso para monitoramento de curto prazo.
5.7 Outros índices compostos no Brasil
O IDHM não é o único índice composto relevante para a gestão pública brasileira. A proliferação de índices sintéticos nas últimas décadas — motivada pelo sucesso do IDH e pela crescente disponibilidade de dados — gerou um conjunto amplo de instrumentos com diferentes objetos, metodologias e escalas de aplicação (Guimarães; Jannuzzi, 2005).
5.7.1 O Índice Mineiro de Responsabilidade Social (IMRS)
O Índice Mineiro de Responsabilidade Social (IMRS) é produzido pela Fundação João Pinheiro com periodicidade anual, com base na Lei Estadual 15.011/2004, que atribui à instituição a responsabilidade pela sua construção. O IMRS abrange cinco dimensões: educação (peso 23%), saúde (peso 23%), vulnerabilidade social (peso 18%), segurança pública (peso 18%) e saneamento e meio ambiente (peso 18%). Para cada dimensão, são selecionados indicadores que captam três aspectos — a situação atual, o esforço das políticas públicas e as características da gestão municipal.
A principal diferença do IMRS em relação ao IDHM é a cobertura anual, o que permite monitoramento mais frequente, e o foco em dimensões diretamente relacionadas à atuação do poder público municipal. Enquanto o IDHM capta o resultado cumulativo do desenvolvimento ao longo do tempo, o IMRS busca refletir o esforço de gestão em curso. O gráfico de dispersão entre IDHM e IMRS para os municípios mineiros revela uma correlação positiva moderada (R² ≈ 0,35), sugerindo que captam fenômenos distintos — o que reforça a complementaridade dos dois índices.
5.7.2 Outros exemplos brasileiros
Guimarães; Jannuzzi (2005) documentam a multiplicação de índices compostos produzidos por institutos estaduais de estatística e planejamento a partir dos anos 1990. Entre os mais citados: o Índice Paulista de Responsabilidade Social (IPRS) da Fundação Seade, que classifica os municípios paulistas em grupos de acordo com riqueza e bem-estar social; o Índice Social Municipal Ampliado (ISMA) da Fundação de Economia e Estatística do Rio Grande do Sul; o Índice de Desenvolvimento Social (IDS) da SEI (Bahia); e o Índice de Qualidade de Vida Urbana (IQVU) da Prefeitura de Belo Horizonte, que usa dados de 75 indicadores distribuídos em 11 setores para as 81 Unidades de Planejamento da cidade.
5.8 Laboratório em R: calculando o IDHM
Nesta seção, reproduzimos o cálculo do IDHM para os municípios de Minas Gerais utilizando dados do Atlas do Desenvolvimento Humano. O objetivo não é apenas obter o índice — é compreender, linha a linha de código, as escolhas metodológicas que o produzem.
5.8.1 Preparação dos dados
options(scipen =999) # evitar notação científicalibrary(readxl)library(dplyr)library(ggplot2)# Leitura da base de dados do Atlas para Minas Geraisatlas_mg <-read_excel("atlas_mg.xlsx")# Inspeção inicialglimpse(atlas_mg)
Rows: 853
Columns: 15
$ code_muni <dbl> …
$ `Nome do Município` <chr> …
$ `IDHM 2010` <dbl> …
$ `IDHM Renda 2010` <dbl> …
$ `IDHM Longevidade 2010` <dbl> …
$ `IDHM Educação 2010` <dbl> …
$ `Subíndice de frequência escolar - IDHM Educação 2010` <dbl> …
$ `Subíndice de escolaridade - IDHM Educação 2010` <dbl> …
$ `Esperança de vida ao nascer 2010` <dbl> …
$ `% de 5 a 6 anos de idade na escola 2010` <dbl> …
$ `% de 11 a 13 anos de idade nos anos finais do ensino fundamental ou com ensino fundamental completo 2010` <dbl> …
$ `% de 15 a 17 anos de idade com ensino fundamental completo 2010` <dbl> …
$ `% de 18 a 20 anos de idade com ensino médio completo 2010` <dbl> …
$ `% de 18 anos ou mais de idade com ensino fundamental completo 2010` <dbl> …
$ `Renda per capita 2010` <dbl> …
A base atlas_mg contém dados do Censo Demográfico de 2010 para os 853 municípios de Minas Gerais, organizados pelo Atlas do Desenvolvimento Humano no Brasil. As variáveis incluem a esperança de vida ao nascer, indicadores educacionais para quatro faixas etárias, renda per capita e os valores oficiais do IDHM — estes últimos servirão como referência para verificar nossos cálculos.
5.8.2 Dimensão Longevidade
A fórmula é a normalização min-max com parâmetros fixos de 25 e 85 anos:
# Subíndice de Longevidadeatlas_mg$i.longev <- (atlas_mg$`Esperança de vida ao nascer 2010`-25) / (85-25)# Os 10 municípios com maior IDHM-Longevidadearrange(atlas_mg, desc(i.longev))[1:10, c("Nome do Município", "i.longev")]
Nome do Município
i.longev
Passos
0.8858333
Nova Lima
0.8850000
Tiradentes
0.8850000
Uberlândia
0.8848333
Itajubá
0.8843333
Viçosa
0.8826667
Barbacena
0.8813333
Guaxupé
0.8801667
Lavras
0.8800000
Perdizes
0.8800000
# Os 10 municípios com menor IDHM-Longevidadearrange(atlas_mg, i.longev)[1:10, c("Nome do Município", "i.longev")]
Nome do Município
i.longev
Santa Helena de Minas
0.7228333
Divisa Alegre
0.7231667
Palmópolis
0.7381667
Pedra Bonita
0.7401667
Setubinha
0.7433333
Pingo-d’Água
0.7438333
Felisburgo
0.7443333
Imbé de Minas
0.7443333
Congonhas do Norte
0.7456667
Mata Verde
0.7486667
Note que pequenas variações na esperança de vida produzem diferenças perceptíveis no subíndice: cada ano a mais de esperança de vida corresponde a um acréscimo de \(1/60 \approx 0{,}0167\) no IDHM-Longevidade.
5.8.3 Dimensão Educação
O cálculo requer duas etapas: construir os dois subíndices e depois combiná-los pela média geométrica ponderada.
# Subíndice de escolaridade da população adulta (peso 1)# Percentual de 18+ anos com ensino fundamental completo, normalizado de 0 a 1atlas_mg$si.escol <- atlas_mg$`% de 18 anos ou mais de idade com ensino fundamental completo 2010`/100# Subíndice de fluxo escolar da população jovem (peso 2)# Média aritmética de 4 indicadores de frequência/conclusão escolar# As colunas 9 a 12 correspondem aos quatro grupos etáriosatlas_mg$si.fluxo <-rowMeans(atlas_mg[, 10:13]) /100# IDHM-Educação: média geométrica ponderada (peso 1 para escolaridade, peso 2 para fluxo)atlas_mg$i.educ <- (atlas_mg$si.escol * atlas_mg$si.fluxo^2)^(1/3)# Rankingarrange(atlas_mg, desc(i.educ))[1:10, c("Nome do Município", "i.educ")]
Nome do Município
i.educ
Montes Claros
0.7437494
Timóteo
0.7419544
Belo Horizonte
0.7365329
Lavras
0.7187650
Itajubá
0.7174683
Araguari
0.7161122
Uberlândia
0.7158870
Alfenas
0.7118534
Juiz de Fora
0.7112161
Confins
0.7110953
arrange(atlas_mg, i.educ)[1:10, c("Nome do Município", "i.educ")]
Nome do Município
i.educ
Araponga
0.3387041
Fruta de Leite
0.3701962
Sericita
0.3750134
Nacip Raydan
0.3772077
Senhora do Porto
0.3776429
São João das Missões
0.3804523
Catuji
0.3818224
Bonito de Minas
0.3876587
Itaipé
0.3882944
Rio Vermelho
0.3892279
O IDHM-Educação tende a ser a dimensão com maior variação entre municípios e, historicamente, aquela que mais contribuiu para diferenciar o desenvolvimento humano dos municípios brasileiros.
5.8.4 Dimensão Renda
O logaritmo é aplicado antes da normalização:
# Subíndice de Renda com transformação logarítmica# Parâmetros: mínimo = R$8,00; máximo = R$4.033,00atlas_mg$i.renda <- (log(atlas_mg$`Renda per capita 2010`) -log(8)) / (log(4033) -log(8))# Rankingarrange(atlas_mg, desc(i.renda))[1:10, c("Nome do Município", "i.renda")]
Nome do Município
i.renda
Nova Lima
0.8641572
Belo Horizonte
0.8407711
Juruaia
0.7944167
Lagoa Santa
0.7897467
Juiz de Fora
0.7838791
Jequitibá
0.7770297
Uberlândia
0.7761368
Uberaba
0.7723307
Caxambu
0.7698870
Poços de Caldas
0.7683296
arrange(atlas_mg, i.renda)[1:10, c("Nome do Município", "i.renda")]
Nome do Município
i.renda
São João das Missões
0.5019105
Santo Antônio do Retiro
0.5036515
Bonito de Minas
0.5137355
Cristália
0.5176785
Frei Lagonegro
0.5187330
Pai Pedro
0.5203964
Monte Formoso
0.5225023
Ninheira
0.5252398
Santa Helena de Minas
0.5314346
Catuji
0.5336122
Nota
Por que o logaritmo? Sem a transformação logarítmica, a dimensão Renda seria dominada pelos municípios de maior renda: a diferença entre R$ 400 e R$ 800 teria o mesmo peso que a diferença entre R$ 1.600 e R$ 2.000, o que contradiz a premissa de retornos decrescentes. Com o logaritmo, a diferença entre R$ 400 e R$ 800 — equivalente a dobrar a renda — recebe o mesmo peso que dobrar de qualquer outro nível.
5.8.5 O índice final
# IDHM: média geométrica dos três subíndices com pesos iguaisatlas_mg$idhm <- (atlas_mg$i.longev * atlas_mg$i.educ * atlas_mg$i.renda)^(1/3)# Ranking finalarrange(atlas_mg, desc(idhm))[1:10, c("Nome do Município", "idhm")]
Nome do Município
idhm
Nova Lima
0.8133898
Belo Horizonte
0.8093619
Uberlândia
0.7892503
Itajubá
0.7866930
Lavras
0.7823665
Poços de Caldas
0.7788983
Juiz de Fora
0.7778448
Varginha
0.7774148
Lagoa Santa
0.7767196
Itaú de Minas
0.7757156
arrange(atlas_mg, idhm)[1:10, c("Nome do Município", "idhm")]
Nome do Município
idhm
São João das Missões
0.5292089
Araponga
0.5356755
Bonito de Minas
0.5366791
Catuji
0.5394526
Monte Formoso
0.5409697
Ladainha
0.5411347
Setubinha
0.5422458
Frei Lagonegro
0.5429932
Fruta de Leite
0.5435173
Itaipé
0.5517140
5.8.6 Verificação do cálculo
Uma boa prática é verificar se os valores calculados concordam com os valores oficiais:
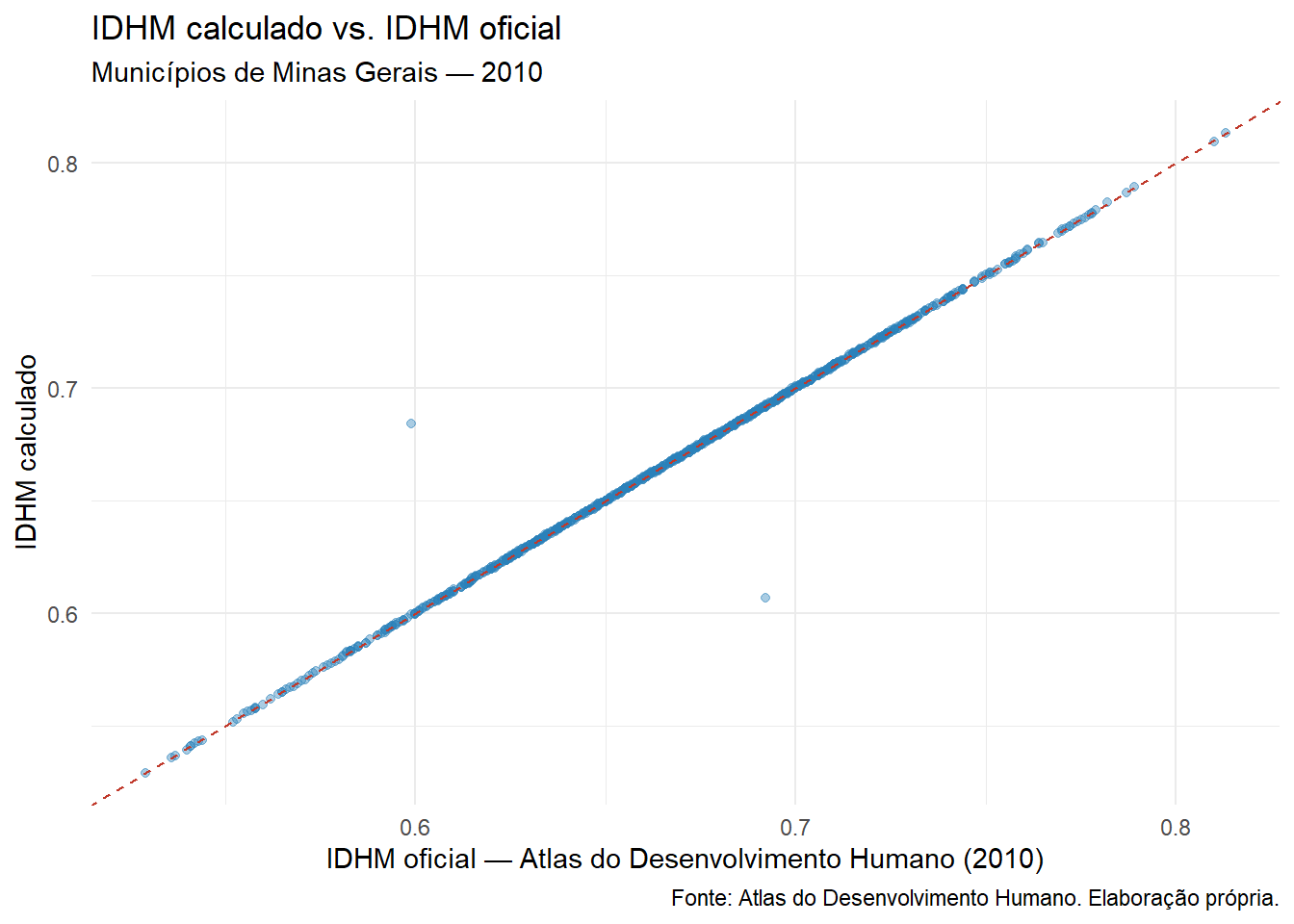
ggplot(atlas_mg, aes(x =`IDHM 2010`, y = idhm)) +geom_point(alpha =0.4, color ="#2980b9", size =1.5) +geom_abline(slope =1, intercept =0, color ="#c0392b", linetype ="dashed") +labs(title ="IDHM calculado vs. IDHM oficial",subtitle ="Municípios de Minas Gerais — 2010",x ="IDHM oficial — Atlas do Desenvolvimento Humano (2010)",y ="IDHM calculado",caption ="Fonte: Atlas do Desenvolvimento Humano. Elaboração própria." ) +theme_minimal()
Figura 5.2: Comparação entre o IDHM calculado e o IDHM oficial — municípios de Minas Gerais, 2010
A linha vermelha tracejada indica concordância perfeita (valores calculados = valores oficiais). Pequenas discrepâncias podem ocorrer em razão de arredondamentos intermediários ou diferenças na identificação precisa das colunas de fluxo escolar.
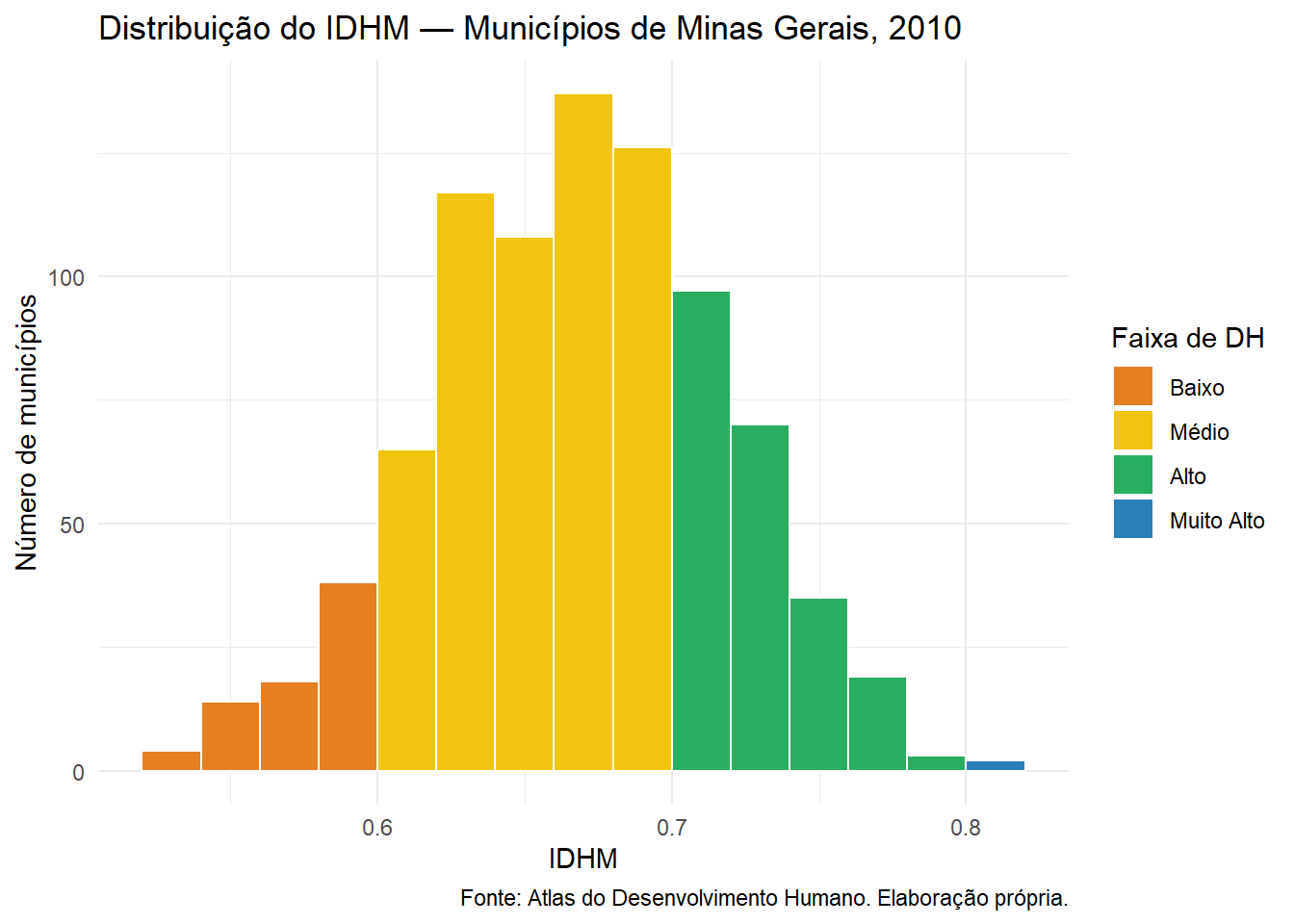
5.8.7 Distribuição do IDHM e classificação por faixas
Figura 5.3: Distribuição dos municípios de Minas Gerais por faixa do IDHM — 2010
# Histograma com faixasggplot(atlas_mg, aes(x = idhm, fill = faixa_idhm)) +geom_histogram(binwidth =0.02, color ="white", boundary =0) +scale_fill_manual(values =c("Muito Baixo"="#c0392b","Baixo"="#e67e22","Médio"="#f1c40f","Alto"="#27ae60","Muito Alto"="#2980b9" ) ) +labs(title ="Distribuição do IDHM — Municípios de Minas Gerais, 2010",x ="IDHM",y ="Número de municípios",fill ="Faixa de DH",caption ="Fonte: Atlas do Desenvolvimento Humano. Elaboração própria." ) +theme_minimal()
Figura 5.4: Distribuição dos municípios de Minas Gerais por faixa do IDHM — 2010
5.8.8 Visualização espacial
A distribuição espacial do IDHM revela padrões geográficos relevantes para a gestão pública. Municípios com melhores indicadores tendem a se concentrar em determinadas regiões, enquanto os piores se concentram em outras — o que sugere a importância de políticas territorialmente diferenciadas.
library(geobr)# Polígonos municipais de Minas Gerais (Censo 2010)mun_mg <-read_municipality(code_muni ="MG", year =2010, showProgress =FALSE)# Juntar dados do IDHM com os polígonos (mun_mg à esquerda preserva a classe sf)base_mapa <-left_join(mun_mg, atlas_mg, by ="code_muni")# Mapa temáticoggplot(base_mapa) +geom_sf(aes(fill = idhm), color =NA) +scale_fill_viridis_c(option ="plasma",direction =-1,name ="IDHM",breaks =c(0.50, 0.60, 0.70, 0.80),labels =c("0,50\n(Baixo)", "0,60\n(Médio)", "0,70\n(Alto)", "0,80\n(Muito Alto)") ) +labs(title ="IDHM — Municípios de Minas Gerais, 2010",caption ="Fonte: Atlas do Desenvolvimento Humano / FJP / IPEA / PNUD. Elaboração própria." ) +theme_void() +theme(plot.title =element_text(size =12, face ="bold"),legend.position ="right" )
Figura 5.5: IDHM dos municípios de Minas Gerais — 2010
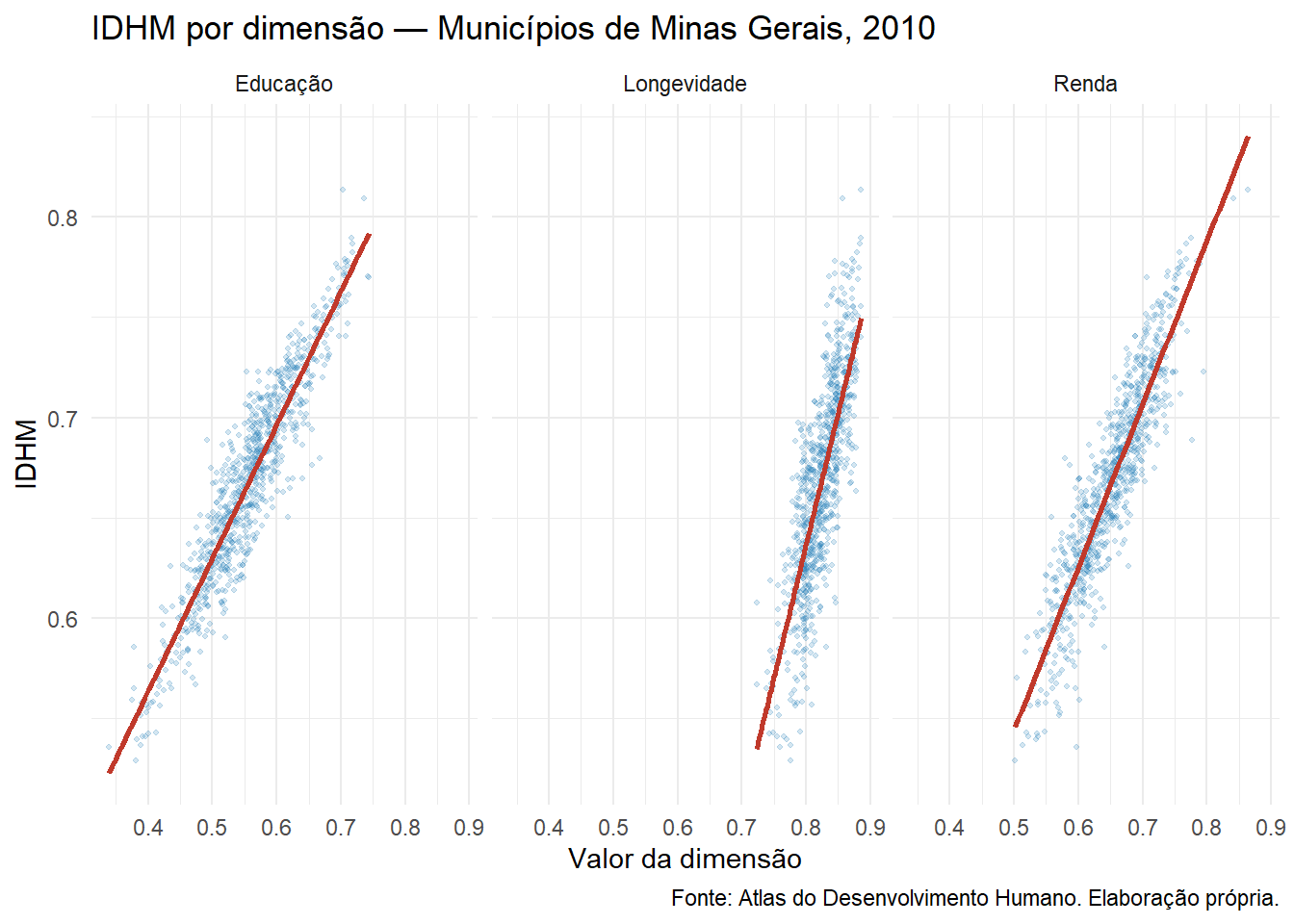
5.8.9 Análise da contribuição de cada dimensão
Uma vantagem do IDHM em relação a índices menos transparentes é a possibilidade de identificar qual dimensão mais explica as variações entre municípios:
library(tidyr)# Reorganizar para formato longoatlas_long <- atlas_mg %>%select(idhm, i.longev, i.educ, i.renda) %>%pivot_longer(cols =c(i.longev, i.educ, i.renda),names_to ="dimensao",values_to ="valor" ) %>%mutate(dimensao =recode(dimensao,i.longev ="Longevidade",i.educ ="Educação",i.renda ="Renda" ))# Gráfico de dispersão por dimensãoggplot(atlas_long, aes(x = valor, y = idhm)) +geom_point(alpha =0.2, color ="#2980b9", size =0.8) +geom_smooth(method ="lm", color ="#c0392b", se =FALSE) +facet_wrap(~dimensao) +labs(title ="IDHM por dimensão — Municípios de Minas Gerais, 2010",x ="Valor da dimensão",y ="IDHM",caption ="Fonte: Atlas do Desenvolvimento Humano. Elaboração própria." ) +theme_minimal()
Figura 5.6: Relação entre as dimensões do IDHM e o índice final — Municípios de Minas Gerais, 2010
Dica
Interpretação: a dimensão que apresentar maior dispersão horizontal com menor inclinação da reta de regressão é aquela que menos explica as variações do IDHM final — ou seja, aquela em que os municípios são mais homogêneos. A dimensão com maior inclinação é aquela que mais diferencia os municípios.
5.9 O que os índices mostram — e o que ocultam
A construção e o uso de indicadores sintéticos são, ao mesmo tempo, necessários e arriscados. A necessidade vem da complexidade dos fenômenos sociais: nenhum indicador simples captura o desenvolvimento humano, a vulnerabilidade ou a qualidade de vida em toda a sua extensão. O risco vem da tendência — observada repetidamente na literatura e na prática de políticas públicas — de tratar o número como equivalente ao fenômeno que representa.
Guimarães; Jannuzzi (2005) documentam como o uso do IDH-M como critério de elegibilidade de municípios para políticas sociais produziu resultados paradoxais: municípios com gravíssimas situações em dimensões específicas — como proporção de crianças em domicílios de baixíssima renda ou inadequação do saneamento — ficavam de fora de programas por apresentar IDH-M relativamente alto, enquanto outros, com IDH-M baixo mas situação razoável nas dimensões específicas relevantes para o programa, eram incluídos.
Isso não significa que índices compostos sejam inúteis. Significa que têm um papel específico — síntese, comunicação, monitoramento geral — e não devem substituir a análise detalhada de indicadores componentes quando a decisão de política pública exige precisão. Como ferramenta de advocacy e monitoramento amplo, o IDHM é valioso; como critério único de elegibilidade para programas setoriais, é inadequado.
A OCDE (2008) resume bem essa tensão: indicadores compostos são como mapas. Um mapa é sempre uma simplificação da realidade — deixa de fora detalhes que seriam essenciais para certas finalidades. Ninguém navega por uma cidade usando apenas um mapa-múndi; ninguém planeja uma política de saneamento usando apenas o IDHM. O que o mapa faz bem — dar uma visão geral, orientar, comparar — é exatamente o que o índice faz bem.
5.10 Resumo do capítulo
Este capítulo apresentou a lógica, a metodologia e os usos e limites dos indicadores sintéticos na gestão pública e na análise social. Os pontos centrais são:
Definição e motivação. Indicadores compostos agregam dois ou mais indicadores simples para capturar fenômenos multidimensionais como desenvolvimento humano, vulnerabilidade e responsabilidade social. Sua principal vantagem é síntese comunicativa; seu principal risco é a perda de informação sobre dimensões específicas.
Etapas de construção. Seguindo o Handbook on Constructing Composite Indicators da OCDE, a construção envolve: definição de marco teórico, seleção de indicadores, tratamento de dados ausentes, análise multivariada, normalização, ponderação e agregação, análise de robustez e comunicação dos resultados.
Normalização. A normalização min-max transforma os indicadores em uma escala de 0 a 1, permitindo comparações. A padronização z-score centra os indicadores na média e os escala pelo desvio-padrão. A escolha afeta a interpretação dos resultados.
Agregação. A média aritmética permite substituibilidade total entre dimensões; a média geométrica penaliza desigualdade entre elas. O IDHM usa a média geométrica em duas etapas: na combinação dos subíndices de educação e na combinação das três dimensões finais.
O IDHM. O Índice de Desenvolvimento Humano Municipal é a adaptação do IDH global para municípios brasileiros, combinando longevidade (esperança de vida), educação (escolaridade adulta e fluxo escolar) e renda (per capita, em logaritmo). O IDHM varia de 0 a 1 e é classificado em cinco faixas.
Limites e boas práticas. Índices compostos ocultam heterogeneidades internas, podem induzir comparações enganosas e são inadequados como único critério de elegibilidade para políticas setoriais específicas. O bom uso exige sempre retornar aos indicadores componentes e manter clareza sobre o que o índice mede — e o que deixa de medir.
5.11 Exercícios
Com base nos dados do atlas_mg, calcule a correlação entre os três subíndices do IDHM (longevidade, educação e renda). Qual par de dimensões é mais correlacionado? O que isso sugere sobre a estrutura do desenvolvimento humano em Minas Gerais?
Replique o cálculo do IDHM usando médias aritméticas no lugar da média geométrica — tanto na combinação dos subíndices de educação quanto na combinação das três dimensões. Compare o ranqueamento obtido com o ranqueamento original. Quais municípios mais sobem ou descem de posição? O que isso revela sobre o efeito da escolha do método de agregação?
O município de Belo Horizonte apresentou IDHM = 0,810 em 2010. Calcule seus três subíndices e identifique a dimensão mais fraca. Que tipo de política pública seria mais adequada para elevar o IDHM de Belo Horizonte a partir desse diagnóstico?
Construa um índice alternativo ao IDHM usando apenas dois indicadores disponíveis na base atlas_mg que você considere relevantes. Justifique sua escolha de indicadores, método de normalização e pesos. Compare o ranqueamento obtido com o ranqueamento do IDHM.
Elabore uma análise crítica do uso do IDHM como critério para distribuição de recursos entre municípios mineiros para um programa hipotético de melhoria do saneamento básico. Que indicador alternativo ou complementar você proporia?